
As your AI project takes shape, data science becomes the central part of the R&D to solve your business issues, whether it is for finding a root cause issue or deploying a prescriptive analytics solution. We’ve condensed what is essential to achieve results, building on the CRISP-DM data mining open standard, useful to drive knowledge discovery projects with feedback loops, while being industry, tool and technologically neutral.
We’ve shared general project management advices from our experts to start an AI project, and in this article we’ll shed some light on the core of an AI project: the data science methodology. Here’s insights from José Andrés García, Wizata’s Lead Data Scientist, to complement the main phases of the CRISP-DM methodology: business understanding, data understanding, data preparation, modeling, evaluation, deployment.
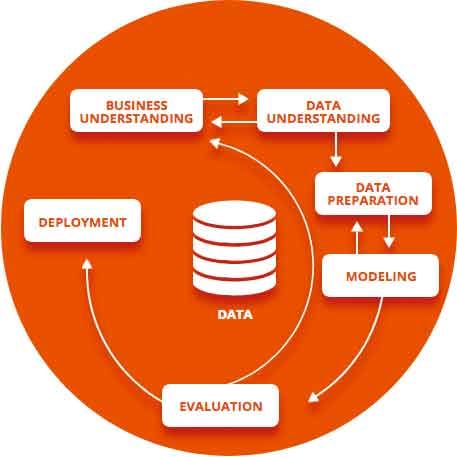
Business understanding
“Together with our client’s experts, we identify constrains and compile materials to make business assumptions. We then define a goal and set success criteria. It’s the teams of our client that have the best experience of their installations, and the more the business problem is understood, the more we as data science and AI experts can precisely and timely identify with our client the data that may help to generate knowledge and achieve impressive results. We usually start with an exploratory workshop, where ideas are evaluated based on complexity, feasibility, availability of required data, ROI potential and other criteria.”
Data understanding
“We’re trying to isolate the right data for the job: if a production line has 2000 sensors, we search together with the client what data could bring the more detailed insight. We check if the data we recommended based on the client teams’ business knowledge is aligned with the problem we aim to solve. We then check all kinds of attributes of this data to check its quality: if it’s valid, accurate, complete and consistent, if the granularity is correct, etc. At Wizata, we generally combine the business understanding phase and the data understanding phase with the feedback loop in a feasibility study, which usually includes a bit of data preparation and modeling to get early insights on what’s possible.”
Data preparation
“In this step, raw data is manipulated, reshaped and refined into information that can be used to construct a model. Special tools and expertise of data engineers are crucial here. It’s important to understand that data preparation isn’t a fixed recipe that can be applied uniformly between projects: the transformed data is molded specifically to the model in construction, which itself is born out of the hypotheses we want to test. For example, sometimes what is analyzed isn’t the data itself, but the rate of change to the data. All in all, a clear business understanding from the start is paramount to generate valid ideas and hypotheses.”
Modeling
“The goal is to select the right algorithm that will help to capture the behavior of the data and generalize it the best. Data scientists’ expertise is fundamental to avoid overfitting, where the trained algorithm doesn’t generalize anymore and simply learnt all data points by heart. It’s a balancing act between a model that gives insights within a defined margin of error and an overfitting model which doesn’t work well with new data.
In the specific case of industry, production lines involve complex processes with time and space restrictions, as well as evolving materials. That’s why we need to understand the production in detail to understand and exploit the data. Applying models assuming everything is fixed can therefore be counter-productive, whereas interconnected models that mimic the processes along the line capture the specificities of the production to give better insights.
At Wizata, we consider that the research stage combines the data preparation and the modeling phases, as they interact within a feedback loop.”
Evaluation
“We iterate between research, modeling and evaluation until we have results with meaningful impact. Through the business understanding phase we generated hypothesis. We then transformed the data during the data preparation phase, and before leveraging it to prove and disprove hypothesis. We then estimate the accuracy and check if the output corresponds to the predefined success criteria.”
Deployment
“This phase can change depending on the projects. For root cause analysis, it sometimes doesn’t make sense to deploy a solution. Other times, deployment isn’t feasible in a single step and must be implemented incrementally. On the other hand, if recommendations from an AI are required every few minutes, deployment is required to capture the data to generate insights. Even more so if real time data is needed for rapid or automatic actions.”
Next steps
“Every project is different and might warrant different steps after deployment. One of these could be continuous improvement or retraining the models with new data.”